
Vertex Shader
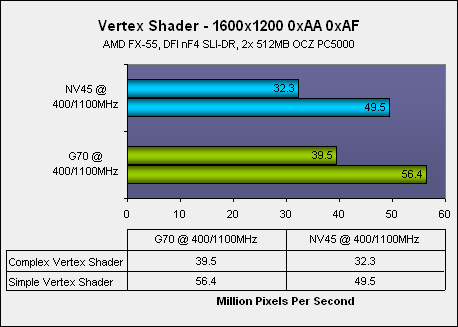
In relative terms, the Vertex Shader has not changed a great deal. In fact, the only thing that is worth noting about the vertex shader engine is that there are more vertex shaders – a 33% increase over NV40/45, going from six to eight. In extremely highlighted situations, we might see a 33% vertex shader throughput; however, this is unlikely unless each vertex shader is operating at 100% efficiency all of the time.We ran some simple vertex-intensive tests in an attempt to find this kind of increase. However, we only found that there was a 13-22% increase in vertex throughput using both of 3DMark05's vertex shader tests, depending on how complex the operations were, and how many vertices there were being processed at any given time.
Pixel Shader
The pixel shader is where NVIDIA have spent a great deal of effort optimising and improving the throughput of each pixel pipeline, allowing for performance that is closer to double what GeForce 6800 Ultra is capable of achieving. NVIDIA have chosen this path rather than just adding more NV40 pipelines in to GeForce 7800 GTX, which would ultimately require faster memory than what is readily available right now.Lack of yield on memory ultimately means that the GPU availability suffers. Hopefully we will not see a repeat of last year this time around, 1.6ns Samsung DRAM modules are fairly widespread now and there shouldn't be problems with memory yields. They have adopted the logic of doing more work per pixel per clock because of the evolution of shader instructions.
Shader Model 3.0 allows for much more complex instructions, and providing each pixel shader is able to perform more work with each pixel, you will not require twice the memory bandwidth to ensure that pixels are stored and then rendered to display in good time.
Optimisation got itself a bad name back around the time of NV3x, where NVIDIA were caught 'optimising' 3DMark03 a little too much for many people's liking. They had a bad chip and were trying to make it look good – many system builders and OEMs base their system specifications around a 3DMark score, rather than how a certain video card performs in real games. NV3x was trash in games but, due to these 'optimisations', the card looked quite good in 3DMark.
Not all optimisations are bad, though. This is an optimisation that will help us to gain massive performance improvements in any title that uses conventional shader instructions, while not having to create a GPU that is bigger than what is manageable on current manufacturing techniques. It's merely an efficiency improvement to the pixel shader, where certain shader instructions will be completed in a single clock cycle rather than two or three clock cycles.
The first test shows that each G70 pipeline is processing close to 9.8 million pixels per second, while each NV45 pipeline is processing a little over 9 million pixels per second at the same clock speed. The second test is slightly different, showing each G70 pipeline to be processing 14.7 million pixels per second as opposed to the 10.8 million that each NV45 pipeline is processing – that's close to a 40% performance increase per pipeline. Add that to the fact that there are 50% more pipelines in G70 and we are looking at a 75 to 105% performance increase over NV45 in the pixel shader, at the same clock speed.




MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.